
Go88 xiaosheng - Link Tải GO88 Chính Thức Năm T7/ 2026
BÀI VIẾT MỚI NHẤT

Xèng 777 GO88 – Slot Đổi Thưởng Hấp Dẫn Tại Cổng Game
Xèng 777 GO88 là một trong những slot đổi thưởng nổi bật tại GO88 apk. [...]

Blackjack Go88 – Trò Bài Hấp Dẫn Đang Có Tại Cổng Game
Blackjack GO88 là trò bài quen thuộc được nhiều người yêu thích nhờ lối chơi [...]

Xóc Đĩa Livestream Go88 – Trải Nghiệm Đỏ Đen Trực Tuyến
Xóc đĩa livestream GO88 thu hút đông đảo người yêu thích đỏ đen trực tuyến [...]
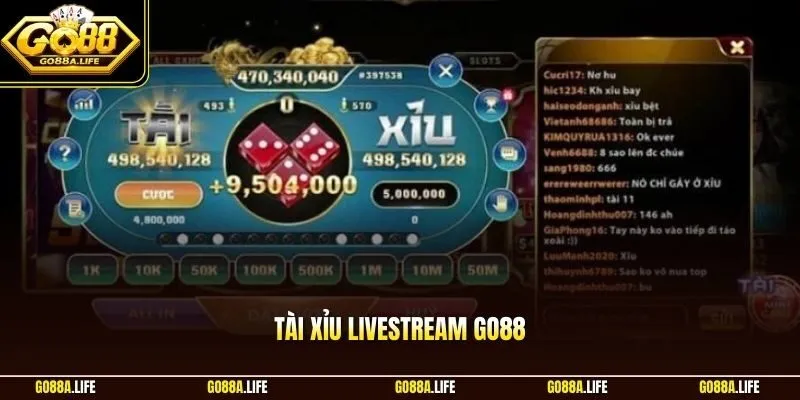
Tài Xỉu Livestream Go88 – Đặt Cửa Trực Tiếp Cực Hấp Dẫn
Tài xỉu livestream GO88 đang trở thành lựa chọn nổi bật dành cho người yêu [...]

Tài Xỉu Go88 – Trò Chơi Xúc Xắc Hấp Dẫn Tại Cổng Game
Tài xỉu GO88 là trò chơi xúc xắc trực tuyến được nhiều người lựa chọn [...]

Xóc Đĩa Go88 – Trải Nghiệm Dân Gian Hấp Dẫn Tại Cổng Game
Xóc đĩa GO88 tái hiện trò dân gian quen thuộc dưới hình thức trực tuyến [...]

Chắn Go88 – Trò Chơi Bài Dân Gian Hấp Dẫn Tại Cổng Game
Chắn GO88 là trò bài dân gian quen thuộc được nhiều người Việt yêu thích. [...]

Cờ Úp Go88 – Trải Nghiệm Cờ Chiến Thuật Hấp Dẫn Nhất
Cờ úp GO88 mang đến trải nghiệm đấu trí lôi cuốn cho người yêu thích [...]